
网络爬虫基础知识
版权申明:本文为原创文章,转载请注明原文出处
工欲善其事必先利其器,多了解一些基础知识,才能更好的知道从哪里下手。
HTTP 基本原理
资源定位
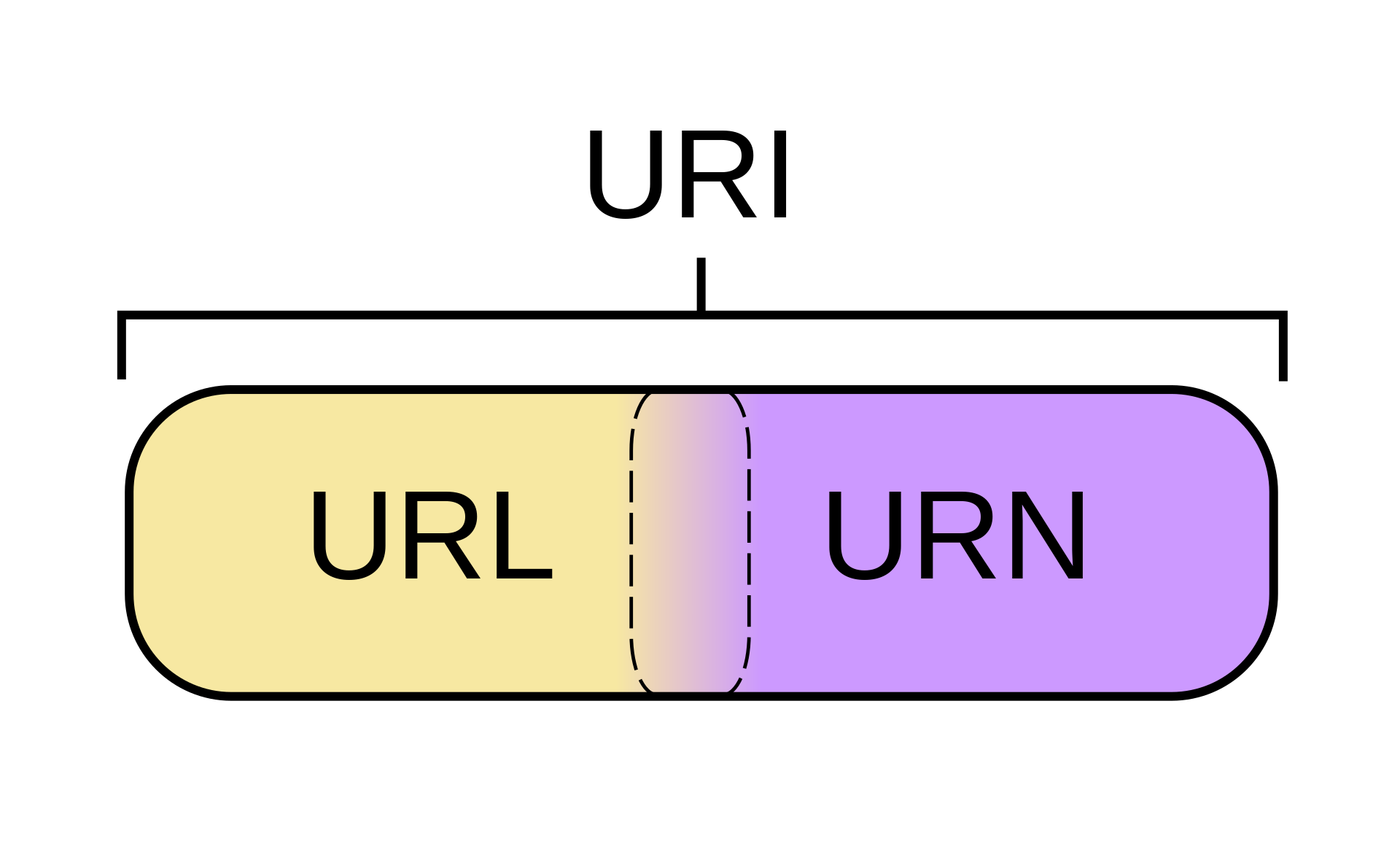
URI(Uniform Resource Identifier)即 统一资源标志符
URL(Uniform Resource Locator)即 统一资源定位符
URN(Uniform Resource Name)即 统一资源名称
URI 可被视为定位符(URL),名称(URN)或两者兼备。
统一资源名(URN)如同一个人的名称,而统一资源定位符(URL)代表一个人的住址。换言之,URN 定义某事物的身份,而 URL 提供查找该事物的方法。
更多信息查看 维基百科链接
超文本
通过浏览器访问的网站就是使用 超文本标记语言(HyperText Markup Language,简称 HTML)编写的,除了展示页面元素还会有一些网络链接。
更多信息查看 维基百科链接
访问协议
一般网页地址的开头会看到 http 或 https,这就是访问资源需要的协议类型。常见的协议还包括 ftp sftp smb 等。
HTTP(HyperText Transfer Protocol)即 超文本传输协议
HTTPS (HyperText Transfer Protocol Secure, 常称为 HTTP over TLS, HTTP over SSL) 即 超文本传输安全协议,主要就是在 HTTP 下面加入了 SSL 层,所有通过它传输的内容都要通过 SSL 加密。
HTTPS 的主要作用是在不安全的网络上创建一个安全信道,并可在使用适当的加密包和服务器证书可被验证且可被信任时,对窃听和中间人攻击提供合理的防护。
越来越多的网站与 APP 都要求使用 HTTPS,例如:
- 苹果要求 iOS APP 在 2017 年 1 月 1 日前全部改为 HTTPS 加密传输,否在 APP 将无法在应用商店上架。
- 谷歌的 Chrome 浏览器,对未使用 HTTPS 加密的网址链接亮出风险提示,告知用户 “此网页不安全”
- 微信小程序要求与后台的通讯必须使用 HTTPS,不满足条件的域名与协议无法进行通信
更多信息查看 Title
HTTP 请求
访问一个网站的过程就是在本地浏览器中输入一个地址,浏览器发起了一个请求(Request)到服务器,服务器对其请求内容做出处理后返回一个响应(Response),浏览器收到响应后显示对应的内容。
常见请求方法:
| 方法 | 描述 | |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单/上传文件)。通常导致在服务器上的状态变化或副作用。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
常见响应状态码与分类:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
Web 网页基础
网页由三部分组成,HTML,CSS,JavaScript。
HTML 相当于房屋主体框架
CSS 相当于房屋的装修
JavaScript 相当于房屋各种开关与电器
一般网页的标准结构:
- html 标签内嵌套 head 和 body 标签
- head 内定义网页的配置与引用
- body 内定义网页的正文内容
在 HTML 中,所有的标签定义的内容都是节点,它们构成了一个 HTML DOM 树。
DOM(Document Object Model)即 文档对象模型,是 web 上构成文档结构和内容的对象的数据表示, 对访问/修改 HTML 的内容提供了接口。
爬虫基本原理
爬虫就是获取网页并提取和保存信息的自动化程序。
爬虫运行的 2 个主要步骤:
- 构造一个请求并发送给服务器
- 接受到响应并将其解析出来
Session Cookies 与 Token
HTTP 是无状态的,后续如果需要处理前面的信息,需要额外传递一些内容。
在服务端,Session 保存用户信息。在客户端,Cookies 保存用户信息。二者共同协作,用来跟踪会话,确保用户访问的有效性。
大多数的应用都是用 Cookie 实现 Session 跟踪的。第一次创建 Session 时,服务端会通过在 HTTP 协议中返回给客户端,在 Cookie 中记录 SessionID,后续请求时传递 SessionID 给服务,以便后续每次请求时都可分辨你是谁。
Session 单机模式下比较适用,如果遇到大并发场景需要服务器集群,就涉及到多个服务器间的 Session 共享问题,或者在多个服务器后面放一个 Redis 来存放 Session。
Token 模式解决了集群共享 Session 的问题,它由一套固定的算法将用户信息与校验信息生成一串特殊的字符,只要签名算法不泄露变可以通过每次请求携带 Token 来判断用户的有效性。
Token 一旦生成无法让其失效,必须等到其过期才行。
Token 一般放在 header 字段中传递。
Token 比较容易做单点登录,跨域跨服务器都很容易校验。

